- The Hidden Layer
- Posts
- An AI Model Using Another AI Model?
An AI Model Using Another AI Model?
Lessons from my Science Fair Project, Part 8
Brandon Kim
November 23, 2025
What was discussed last week…
Just because a research paper was released very recently, doesn’t mean that it’s more valuable than a previous research paper.
This principle also applies to new AI models!
What matters, however, is the relevance to your topic of concern or interest.
Thurs >> Nov 20
This week, I was training one of my main models for my science fair project, but after several hours, it seemed to plateau at ~0.83 accuracy (which is measured by the Dice Similarity Coefficient, or DSC).

So in order to improve my current model, I thought of implementing another model that could take in the “raw” data, and then pass the output of that data onto the original model that I was training. This concept, I later learned, was called a “pipeline”, and it can apply in many other AI fields too, not just in research.
Fri >> Nov 21
Today, I decided that my pipeline was going to consist of two models: one deals with “object classification” which locates and identifies objects in a 3d model using “bounding boxes”, and the second model is the original model that I had tested before.
My original model’s task is image segmentation, which means tracing the outline of a certain object or multiple objects that’s wanted from an image or 3d model.
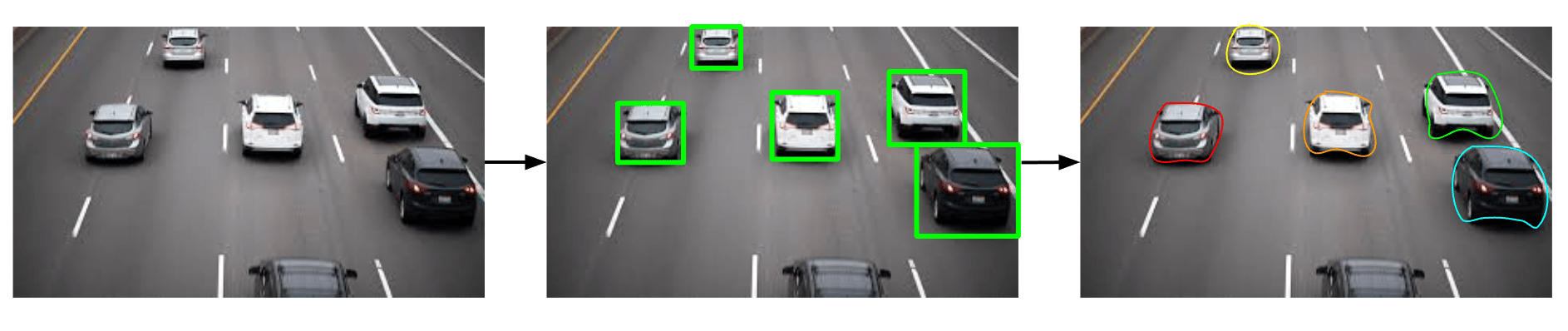
The rationale behind this strategy was to get one model to recognize the rough “pin-drop” locations of the objects using object detection, and then the actual image segmentation model to outline the object’s shape and identify it.
This image segmentation approach was used in a few research papers that I looked into, and they’ve specifically use the YOLO architecture to accomplish object classification, so I tried using that.
Sat >> Nov 22
In “pipelines”, the output data from one model can either be automatically or manually transferred to another model. For example, when an AI email analyzer takes a set of incoming emails and then filters and sends relevant emails into a Slack channel, the pipeline does this automatically, and is called a sequential pipeline. Non-sequential pipelines, in contrast, may not automatically transfer data between models and processes automatically, and thus will require manual transferring (e.g. through copy pasting, sending files, etc). Non-sequential pipelines can also have multiple inputs and outputs, depending on the use case.
My model pipeline in this case, would be a sequential pipeline, because the output of one model is going straight into another model.
Also, during the training of the YOLO model, I “froze” the model so it could adjust to my data. When I copied over the YOLO model architecture, I also copied over its weights, which are like it’s “learnings” from a certain training session. So, to keep some of the weights intact, I froze pars of the YOLO model. “Freezing” a model some layers' weights from changing during training. It is done to keep the pre-trained knowledge while adjusting the rest of the model to new data.
This “copying” over of weights is called transfer learning.
Lessons Learned
“Pipelines” are series of models and processes in AI and machine learning that consists of models that process data through a linear fashion, where the first model’s output becomes the second model’s input, and so on.
“Freezing” models happens when only certain parts of models need to be trained, and is useful in transfer learning.